这一章的主要思想就是“三个臭皮匠赛一个诸葛亮”。一般而言,我们都是通过一个分类器进行分类,但是一个分类器可能会出现偶然误差错误,就像一个人总会出现失误一样。所以,我们学习多个不同的分类器,然后将这些分类器通过加上不同的权重组合起来,就形成了一种强大的集成分类器。而这其中,可以再次改进,对不同的分类器,分类效果不同的,权重也可能不同,这样,分类效果好的分类器能够得到更大的“投票权”
前言
- 元算法/集成学习:即考虑多个专家的意见而不是一个人独断专权
- AdaBoost:
- 优点:泛化错误率低,易编码,无参数调整,可使用在大多数分类器上
- 缺点:对离群点敏感,即对极端值拟合不好(如极大极小值)
7.1 数据如何划分–多重抽样分类器(集成学习的分类)
- 7.1.1 bagging:Bootstrap aggregating,引导聚集算法/装袋算法
- 原理:从原始数据总随机有放回的抽取n次组成一个数据集,训练为一个分类器。这样重复进行m次,就得出m个分类器。分类器的权重相等。记住这些分类器数据集是并行进行的,与boosting有区别。
- 改进算法:随机森林(random forest)
- 7.1.2 boosting(Boost–增强)
- 原理:与bagging类似,不同的是,每个分类器的数据集不是并行的,而是串行的。即每个新的分类器都是根据已经训练出来的分类器的性能来进行训练的,之后的分类器需要使用到之前已经训练好的分类器的数据集。boosting集中关注那些被错误分类的数据集。
- bagging分类器的权重是相等的,boosting的权重是不相等的,每个权重代表的是分类器在上一次迭代时的成功度。
- boosting的版本有很多,AdaBoost是其中一种(AdaBoost–Adaptive Boosting–自适应增强)
7.2 原理和算法
- 这里含有许多的公式证明,即为什么使用这些公式,而不使用其它的公式,其中的道理,很难说的清除,暂且保留(可参考《统计学习方法》P139,《西瓜书》P175)
- 第一个分类器的权重alpha:
- 定义错误率w = (被错误分类的样本)/(样本总数)
- alpha = (1/2)*ln((1-w)/w);即错误率越低,权重越大。实际代码操作,变化巨大
- 一个分类器中每个样本的权重更新:
- D = D * exp(+-1 * alpha) / sum(D);被正确分类则为-1,否则为+1。注意:这里在代码中有技巧,因为标签为+-1,可以抵消
7.3 单层决策树–决策树桩(decision stump)
- 代码boost.py
1 | """ |
- 代码adaboost.py
1 |
|
- 测试代码test.py
1 | """ |
后续:
- 非均衡分类器
–| 即训练出来的分类器并不是一定准确的,即便错误率很低,但是在某些情况下在这种错误是不能出现的。比如,垃圾邮件的分类,本来是好的邮件被当做垃圾邮件会造成邮件的丢失。
–| 一般而言,这种分类器是由于正例样本和反例样本数目相差很大造成的。
- 分类的其他度量指标:正确率、召回率、ROC曲线
- 1正确率:前面使用的就是正确率来度量,但是我们可以改进前面的度量方式。如采用混淆矩阵(书中后面讲到的代价函数)
- 2召回率:预测为正的数据占所有实际为正例的比例。在召回率很大时,真正判错的正例不多
- 3ROC曲线,当面积AUC越大,说明分类器越好,作为模型选择的一种方式
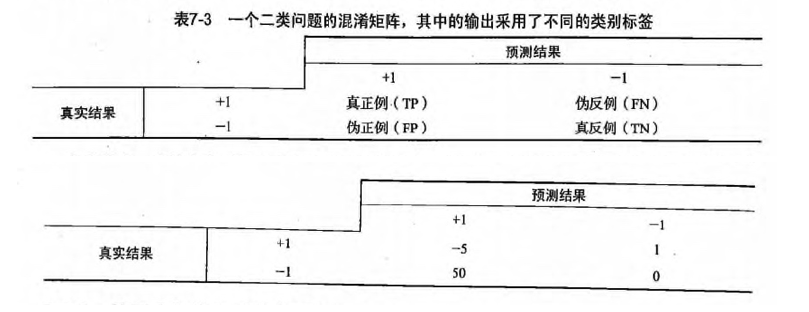
- 处理分均衡问题的数据抽样方法
即对某一个类别的样本少的进行重复抽样–过抽样;对样本多的进行少抽样或删除–欠抽样
总结:集成分类器可能进一步突出单个分类器的不足,如过拟合问题;但是如果分类器之间的差别较大时,这个问题就会缓和一些。这种不同可以使算法不同,也可以是数据不同。

