Fork/Join 模式类似于MapReduce,也相当于一种分而治之的理念,或者说就像二分查找、二路归并算法。通过将一个大量的计算分解为许多的小计算,分而治之,然后再合并,同时,这些分出来的每个小计算都是并行进行的,这样就大大增大了CPU的利用率。
Fork/Join 模式有自己的适用范围。如果一个应用能被分解成多个子任务,并且组合多个子任务的结果就能够获得最终的答案,那么这个应用就适合用 Fork/Join 模式来解决。图 1 给出了一个 Fork/Join 模式的示意图,位于图上部的 Task 依赖于位于其下的 Task 的执行,只有当所有的子任务都完成之后,调用者才能获得 Task 0 的返回结果。可以说,Fork/Join 模式能够解决很多种类的并行问题。通过使用 Doug Lea 提供的 Fork/Join 框架,软件开发人员只需要关注任务的划分和中间结果的组合就能充分利用并行平台的优良性能。其他和并行相关的诸多难于处理的问题,例如负载平衡、同步等,都可以由框架采用统一的方式解决。这样,我们就能够轻松地获得并行的好处而避免了并行编程的困难且容易出错的缺点。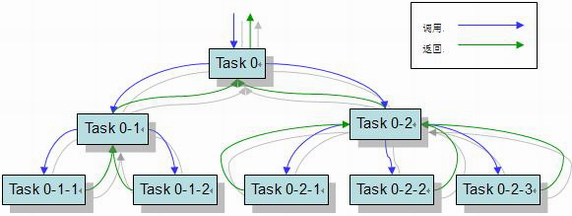
在多线程并发编程中,有时候会遇到将大任务分解成小任务再并发执行的场景。Java 8新增的ForkJoinPool很好的支持了这个问题。ForkJoinPool是一种支持任务分解的线程池,当提交给他的任务“过大”,他就会按照预先定义的规则将大任务分解成小任务,多线程并发执行。 一般要配合可分解任务接口ForkJoinTask来使用,ForkJoinTask有两个实现它的抽象类:RecursiveAction和RecursiveTask,其区别是前者没有返回值,后者有返回值。
应用场景:
简单来说:如果你的问题能很容易分解成子问题,则比较适合ForkJoinPool。适合CPU密集型的场景。实例:计算1+2+…+100;并行计算
1 | package com.sound.daytc1; |

