redis不提供严格的锁机制,即不保证数据的完全正确性,所以需要用户自己去严格检查。为了保证数据的安全,需要将数据及时的存储到硬盘上,redis提供两种持久化的方式:快照-批量写入;追加-单条追加。另外为了保证数据库的安全,防止数据丢失和为了负载均衡,redis也提供了分布式情况下的复制策略,可以对多个服务器数据进行同步。另外,根据不同的场景,我们需要合理的判断形势,在性能和安全上达到一个平衡,即既能够快速的处理数据,又能够有效地避免数据的丢失。
4.1 数据持久化
快照snapshotting
快照即对数据进行批量备份,之前的备份数据将被删除。创建快照的方式有以下几种:- 通过bgsave创建快照,这种方式下,redis会通过调用fork来创建一个子线程,子线程负责将快照写入硬盘,而父线程还是继续执行接下来的步骤。
- 客户端直接向redis发送save命令来执行快照,这时,redis在完成当前快照之前,将不再响应其他命令,可以避免新的数据写入,不存在丢失情况。但是这种情况并不常用,我的思考:因为redis就是用来高并发的,如果需要等待,还不如不用;另外,save命令使用在以下场景,即bgsave命令时,没有足够的内存(这种情况需要避免),或者并不需要太高效率,完全可以等待持久化操作。
- 用户通过
save 60 10000命令来控制bgsave的时间,这段话代表,60秒之内有10000个写入时,将触发bgsave命令。redis在接收到关闭服务器请求时或者接收到TERM信号时,将会触发save命令,阻塞所有客户端,并在save命令执行完毕后,关闭服务器。从而保证数据保存正常。 - 另外在都服务情况下,当主服务器向从服务器进行数据复制时,即SYNC命令。主服务器需要对自身数据进行快照,即执行bgsave命令。(如果是刚刚执行,则不再执行,如何判断?应该是有个时间字段判断~)
缺陷:*
通过快照的逻辑发现,快照是用来保存数据到磁盘上,如果没有及时快照,比如在下一次快照之前,系统奔溃,那么内存中还没有被快照的数据将永久丢失,所有,快照持久化只适用于那些即便丢失部分数据,也并不会造成问题的情况,比如视频数据。场景*
1 一般而言对于bgsave命令,根据不同的场景,时间任务设定也不尽相同,因此为了更加贴近实际,需要开发场景和生产场景尽量相同
2 另外为了防止数据丢失,需要保存日志,一边在之后根据日志来恢复数据。
3 由于bgsave命令需要创建子线程,对于20G的大数据处理,将会存在间断性的停顿,但是对于save,速度将大大加快。为了降低停顿对用户体验的影响,我们可以选择低峰时间段进行快照,比如凌晨3点。追加append-only file
快照能够将大量数据进行写入,这样数据存储将能够很好地组织,也便于查询,但是容易导致大量数据丢失。而AOF追加,通过只在AOF文件后进行追加,从而及时的添加当前的信息。文件同步:write和flush命令,write会将把数据存储到缓冲区,然后等待操作系统将数据写入硬盘,flush则会请求操作系统将数据尽快写入硬盘。
AOF有三种选择,每个命令执行一次,每间隔一秒执行一次;让操作系统自己判断执行时间。为了兼顾安全性和写入性能,一般使用每间隔一秒执行一次追加。
- 重写/压缩AOF
前面,我们已经知道了,AOF操作通过追加,可以将文件的丢失控制在一秒以内,从而大大防止数据的丢失,但为什么不直接使用这种方式,还使用快照呢?原因在于,每一次AOF都会产生命令记录AOF,这样就会导致AOF文件越来越大,最终可能沾满硬盘空间,所以,为了避免这种情况,AOF提供了重写功能,即压缩数据,类似于java垃圾回收中的复制整理,通过将数据进行重新整理,去掉冗余的数据,将大大降低磁盘的空间。
AOF重写命令也有两个,BGREWRITEAOF和AUTO..,这两个命令的逻辑同bgsave/save类似,也是通过是否开子线程来进行数据重写操作。
- 重写/压缩AOF
4.2 复制
为了满足分布式服务器结构,数据与数据之间的互相备份,redis提供了复制功能。通过复制功能,就可以大大降低单个redis的负载,从而实现负载均衡。- redis的复制功能需要配置主从服务器,具体参数参考相关文档
- redis在进行复制时,将擦除从服务器的所有相关数据;另外由于主服务器进行复制时将创建子线程,将大大占用内存,所以,为了防止效率低下,在内存初期配置时,最好预留一部分内存,即主服务器只是用60-70%的内存。
- 主服务链:有时候我们可能会这样设计一个服务群,一个主服务器,和100个从服务器,但是这样是否很好?如果100台服务器同时请求复制,那么主服务器的压力将很大很大,所以,为了进一步降低服务器的压力,我们使用了服务器链(有如树结构),如下图,每一层的服务器都相当于下一层服务器的主服务器,每一个主服务器的连接点都不会太多,这样,顶端的服务器压力将会分配给下面的所有服务器。
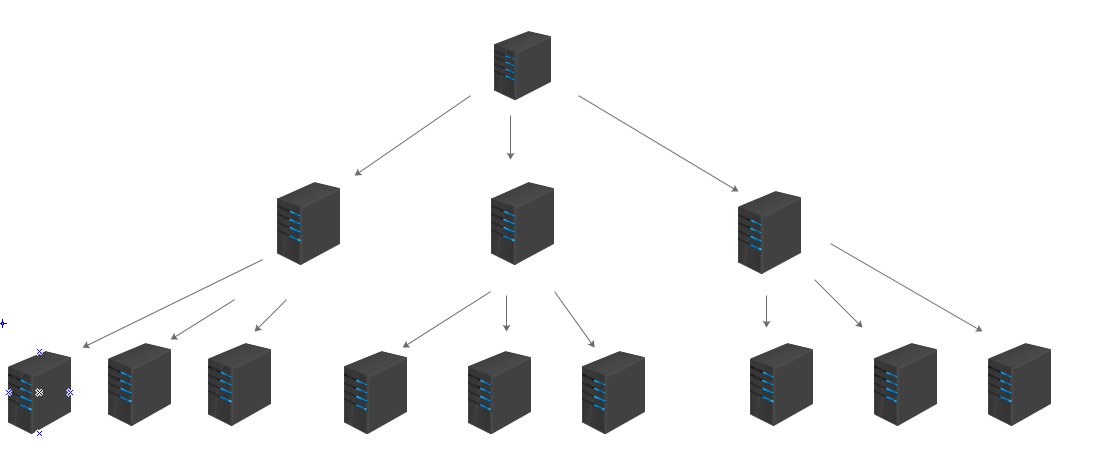
磁盘检查
为了验证主服务器是否已经将数据发送到从服务器,需要向主服务器发送一个唯一的虚构值,这个虚构值也将发送到从服务器,通过检查从服务器是否含有虚构值就可以判断,是否发送成功。4.3 处理系统故障(略)
4.4 Redis事物
redsi事物并不同于mysql中的事物,即它并不会保证事物的原子性和自动回滚,需要用户自己设置判断。具体信息如下:单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。
事务可以理解为一个打包的批量执行脚本,但批量指令并非原子化的操作,中间某条指令的失败不会导致前面已做指令的回滚,也不会造成后续的指令不做。
例子:如下的例子为模拟游戏商城中,卖家发布自己的商品,和卖家购买商品的逻辑。4.5 非事物型流水线
通过上面的redis事物,我们知道,redis的事物并不是真正意义上的事物,而是由两部分组成,一部分为通过pipeline流水线,批量执行命令,这样大大增加写效率;另一个通过使用multi和exec命令,保证当前的事物不被其他客户端干扰,从而一定程度上避免数据冲突。我们发现,如果我们并不需要数据安全,但是,觉得单个命令执行过慢,那么,是否就可以使用事事务的第一个逻辑,进行批量写入,即只使用流水线功能,但是不屏蔽其他客户端。例子如下:总结
数据库总是在读入和写入之间达到平衡*,写入快(如追加),则查找慢(数据不规律);写入慢(进行有规律的写入),则查找就快。之所以导致这个原因,是由于硬盘的逻辑结构和物理逻结构并不相同,我们存储时,都是根据物理结构,但是查找使用逻辑结构,所以效率降低。
另外,数据库存储总是在安全和性能之间平衡,为了安全就必须对数据进行严格检查加锁,但是为了效率,又必须进行加锁同步,而不是异步执行。所以,需要找到一个折中,如果数据安全不是太严格,就可以适当降低安全限制,使用乐观锁。但此时,用户需要自己创建检查。
1 | import redis.clients.jedis.Jedis; |

